Replication
Sinewave replication of a natural utterance
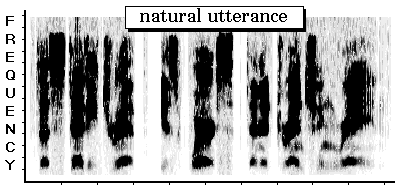
The display above is called a spectrogram, which provides an acoustic "picture" of a speech utterance. In this type of display time is represented on the horizontal axis, frequency on the vertical axis, while amplitude corresponds to the darkness.
The spectrogram above illustrates natural speech acoustics: the regular vertical striations are due to glottal pulsing (caused by the activity of the vocal cords); the broadband formats (the dark horizontal bands) are each a natural resonance sustained by the column of air enclosed by the vocal tract between the larynx and the lips; aperiodic sources and transients can be attributed to consonantal releases (e.g. /b/, /d/ sounds), frication (e.g. /s/, /v/ sounds), and aspiration (e.g. /h/ sound).
The spectrogram above was obtained by analyzing the utterance: "The steady drip is worse than a drenching rain."
The sinewave replication
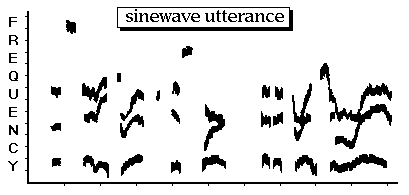
A sinewave replica of a natural utterance (shown above) discards the fine-grain acoustic properties of speech, retaining only the coarse-grain changes in the spectra over time. This pattern of spectral changes is estimated by linear prediction or another method of spectral peak-picking. The result is a record of formant center-frequencies and amplitudes at regular intervals throughout an utterance. When this numerical description of the spectra of an utterance is used as the parameter set for the SineWave Synthesizer (SWS), the result is a pattern of sinusoids, each one fit to the frequency and amplitude track of a formant in the natural utterance. Without imitating the spectra of the actual signal components, a sinewave complex replicates the overall pattern of spectral changes of the utterance. Phonetic information is preserved in these changes, and is evidently not the sole preserve of the traditional momentary acoustic "cues."
The spectrogram above is of a sinewave replica of the utterance: "The steady drip is worse than a drenching rain."